Exploration of software projects with large code base looking at keyword frequency distributions. Surprisingly (or not so surprisingly) they roughly follow the famous Zipfian distribution.
I was reading a book on genomics named The Violinist's Thumb when I got the idea behind this post. The basic idea of the book is how our lives are written by our genetic code. Along with the connectome, I believe the idea defines the whole life of an individual.
Meanwhile in the reading, the book showed me a beautiful empirical law. The Zipf's law. When George Kingsley Zipf was playing with classic literary works, he discovered a pattern in the frequency distribution of words.
- The second most used word has half the frequency as compared to first most frequent word.
- The third most used word has one third the frequency as compared to the first most frequent word and so on. . .
This is Zipf's law. Now the amazing bit. Since then, the Zipfian (the frequency distribution following Zipf's law) distribution has been seen in music, city population, mass extinctions, earthquakes and even DNA.
Originally, the explanation Zipf gave for the phenomenon was the Principle of least effort. According to Zipf, the principle governs the transfer of information via the path of least effort and this explains the relation between variations and repetitions.
Seeing such a pattern in human languages led me to search if this works for computer languages. Although I didn't expect anything, since the structure of human and computer languages aren't exactly same, but I gave it a try. Similar to words in human language, I took keywords in computer languages, since variable names and other things aren't as frequent as keywords. Saying that, I do realize that this is not exactly the way this should be done, but it should work as a crude approximation.
1. Results
Below are the plots of keyword frequencies (few top keywords) for various software projects along with the approx Zipfian distribution. The projects here are dominated by (almost) one single language and are large projects as far as lines of code are considered, this might be better for finding such patterns.
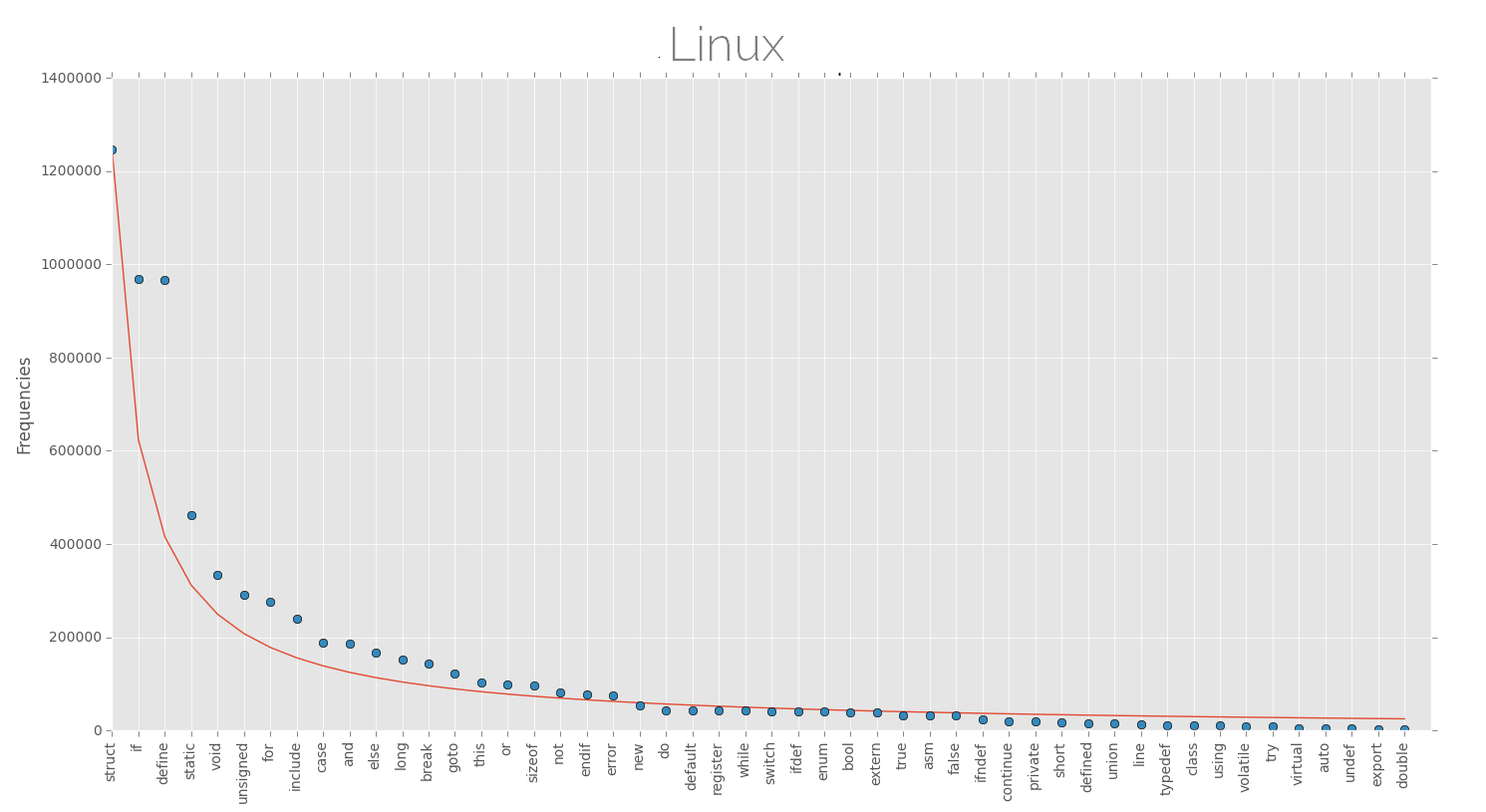
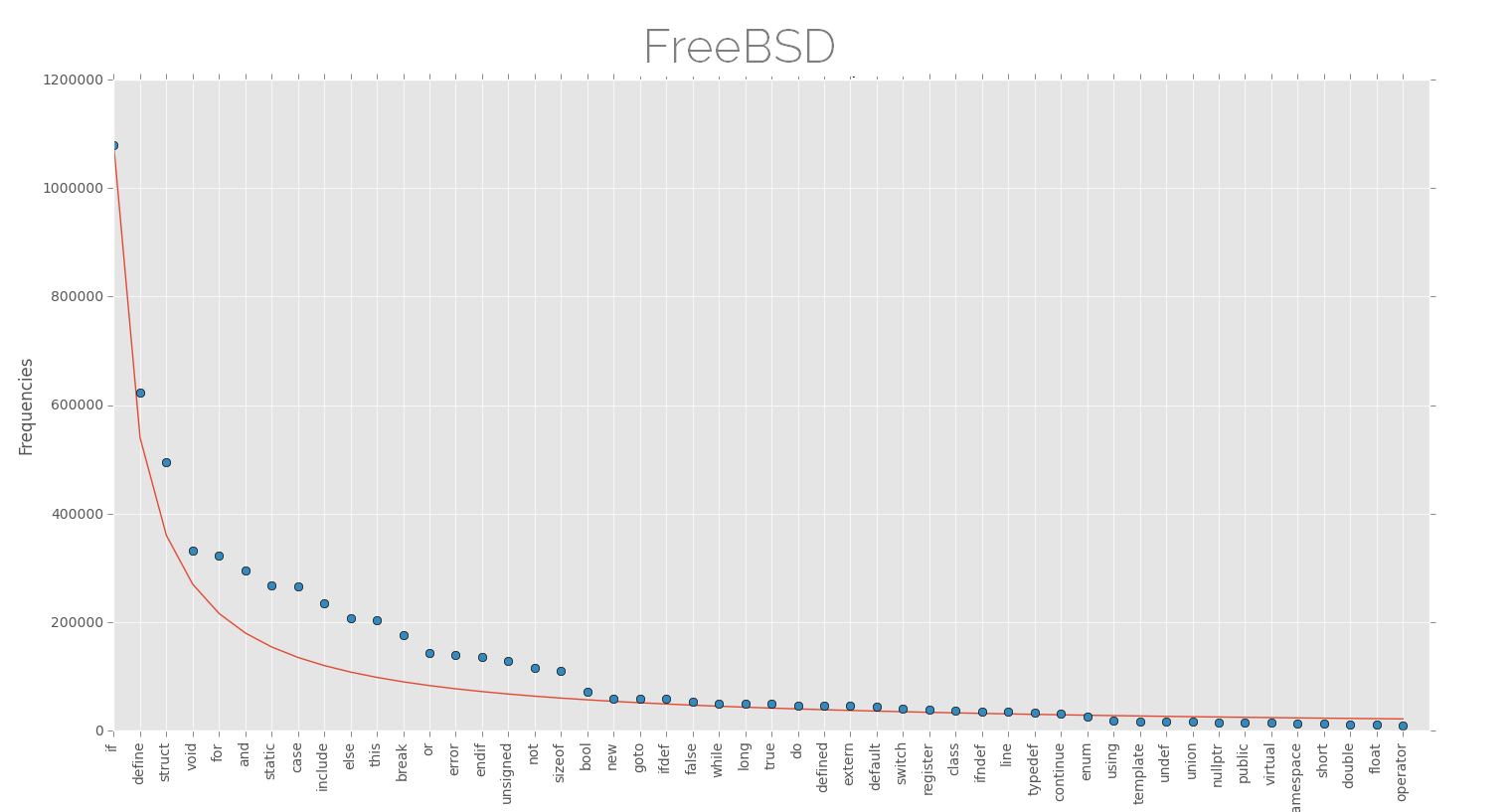
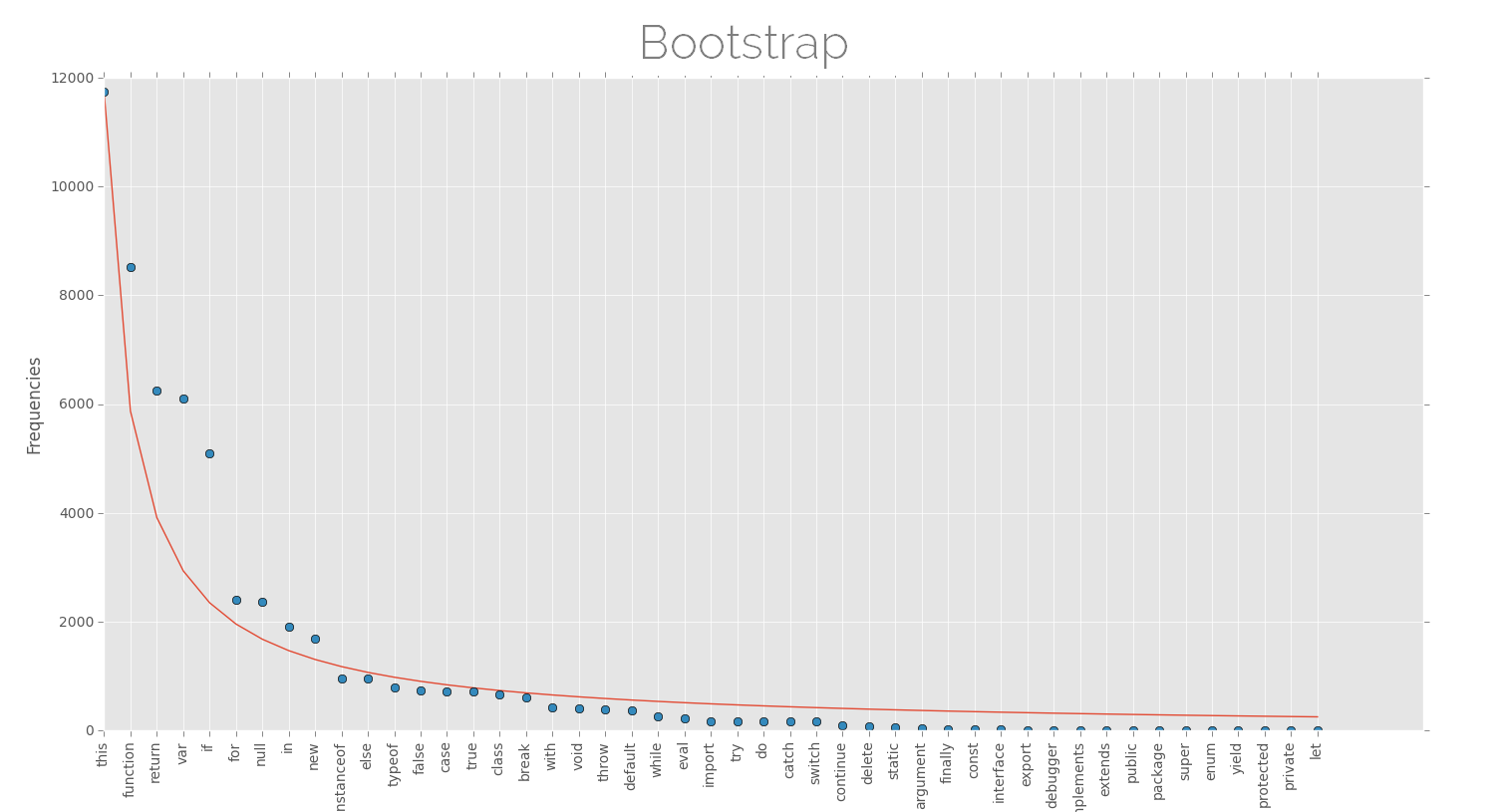
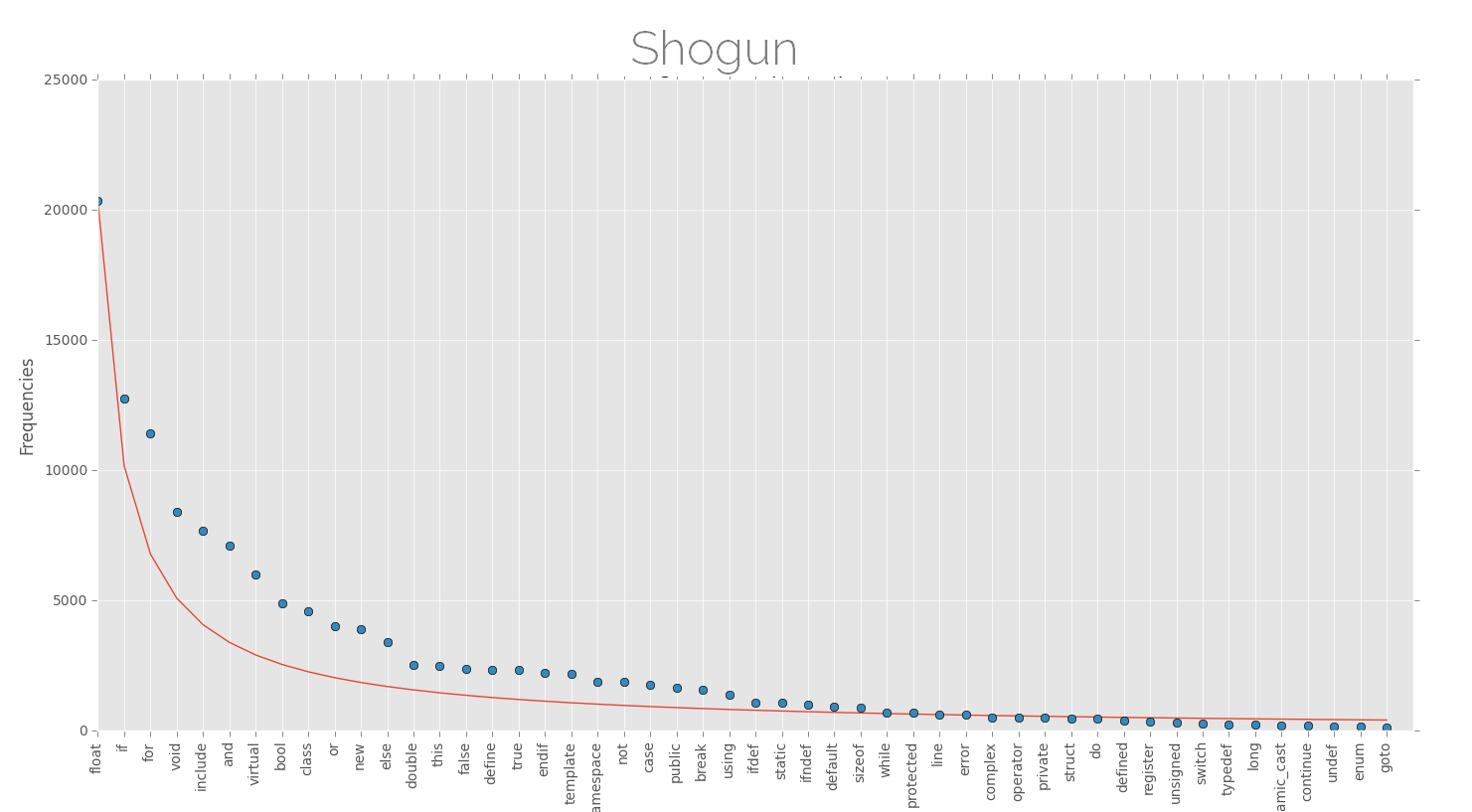
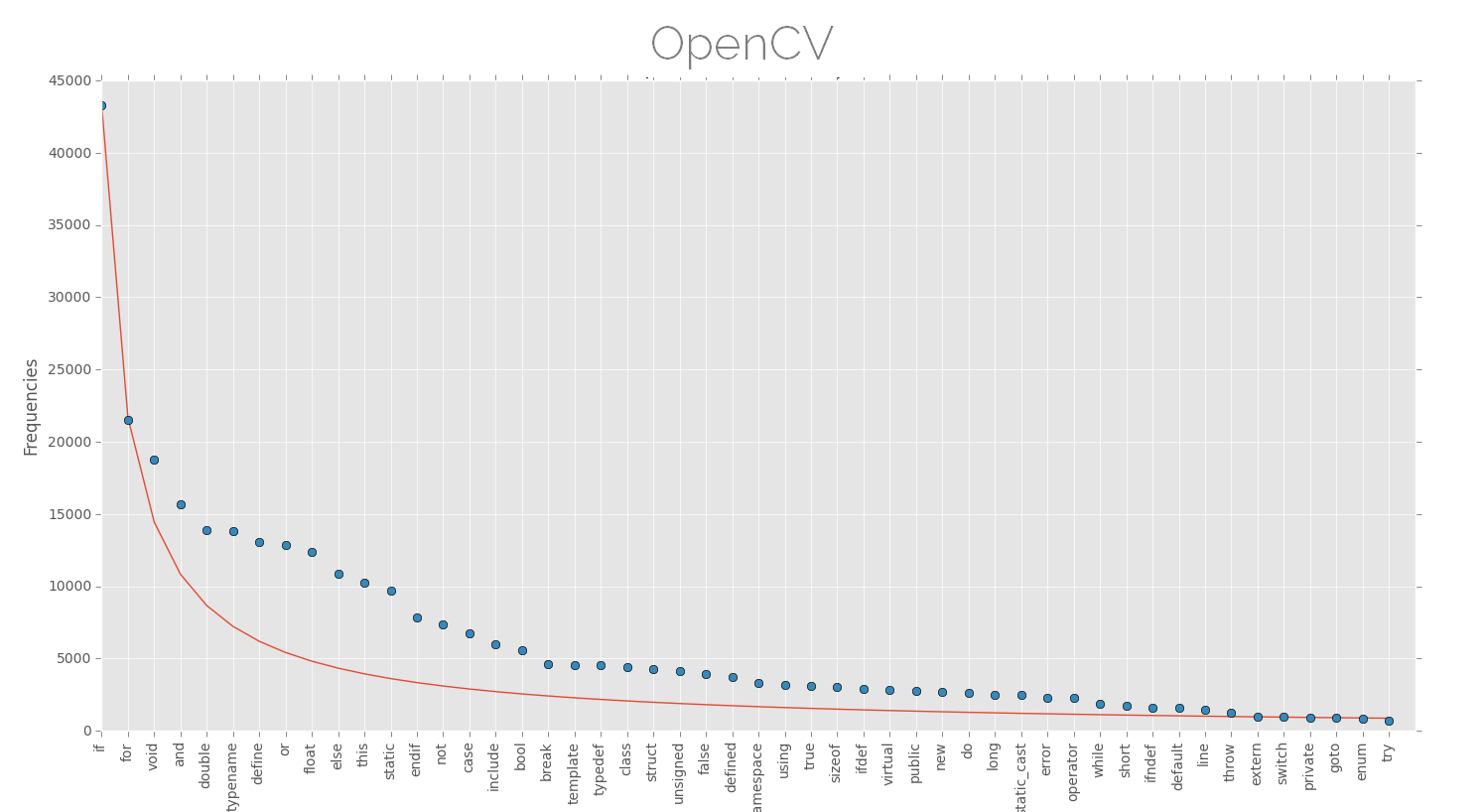
Ah! I don't know if I can declare this, but the distributions look nice. The law of least effort or anything else. Although there is high probability that these are not representatives of Zipf's law, but nevertheless, its fun to see something like this.
There are many power laws in nature that tend to line up observations in a specific order. Individually, things don't show up, but on a crowdish scale, the patterns begin to emerge, consider population, species, social networks, crowd behavior, star clusters, sub atomic particles . . . everywhere.
This feels like toy mathematics, like knot theory, but there are serious implications, and there maybe more. Here is an excerpt from the Wikipedia article on long tail
In his Wired article, Chris Anderson cites earlier research [17] by Erik Brynjolfsson, Yu (Jeffrey) Hu, and Michael D. Smith, who first used a log-linear curve on an XY graph to describe the relationship between Amazon.com sales and sales ranking. They found that a large proportion of Amazon.com's book sales come from obscure books that were not available in brick-and-mortar stores. They then quantified the potential value of the long tail to consumers. In an article published in 2003, these authors showed that, while most of the discussion about the value of the Internet to consumers has revolved around lower prices, consumer benefit (a.k.a. consumer surplus) from access to increased product variety in online book stores is ten times larger than their benefit from access to lower prices online. Thus, the primary value of the internet to consumers comes from releasing new sources of value by providing access to products in the long tail.
Anyway, the exciting thing about living in current time is that we have data. Much more than what Zipf had.