Goodreads feels like a project with a lost focus. I can list a dozen (about right) things that don't justify the prefix of the project's name. Don't get me wrong here. The content there is really good. The collections, lists people make, most reviews, they all are good. What's not good is the product itself. It looks like no one is developing it any more. Rightly so if maybe the users are satisfied.
Its search doesn't provide what you expect from all modern search interfaces. Try turning on infinite scroll in your shelves and keep going down only to learn about random sampling. Oh and the clutter in the default setting of your feed. Everything and more made me switch to a scheme where my reading data is more bare, accessible and manageable without the noise.
1. A better list
My usual book reading cycle involves doing a web search (not goodreads') after I
become aware of a title and landing on goodreads to mark it as to-read. Then
rating it and possibly writing something about it. I don't tend to maintain
multiple shelves because maintaining that isn't a very smooth process on the web
ui.
I am now using an org file for my reading-list with a little bit of Emacs scripting which lets me import books from amazon and goodreads urls. Thankfully, there is csv export feature in goodreads which lets you export all you books in a single csv, which is easy to pull in.
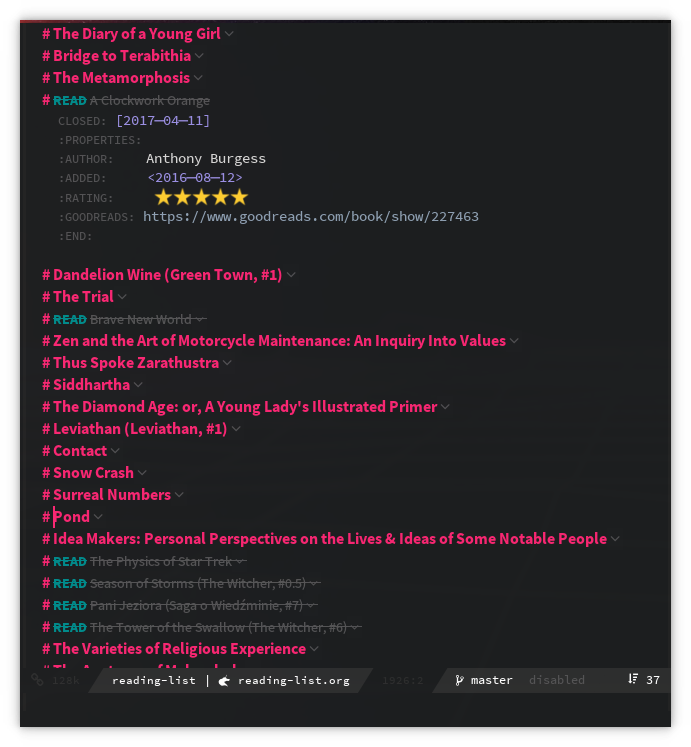
Keeping an org file has some neat benefits. I can pull readings in my agenda view, create progress indicators separate from the shelves (which can go in org tags), attach arbitrary content to entries, create innumerable custom and dynamic views for the library, write richer reviews etc. I am still experimenting with it but I believe it would fit right in with my needs and would quickly become what I want it to be.