In the last EmacsConf, I had a talk in which I was running a few semantic queries in Emacs via an external Python server. Someone pointed that the usability of this system is going to be low if I have to run a separate process for ML tasks. That pushed me to make ONNX.el for running models in ONNX format. I then built tokenizers.el to convert text to tokens. Finally I wrapped everything together in sem.el which provides high level semantic search functions that run inside Emacs as dynamic modules without needing any external process or API.
By default sem runs a local all-MiniLM-L6-v2 model for text embeddings. This
model is small and runs fast on CPU. Additionally, we load an O2 optimized
variant which helps further. The vectors are stored in a lancedb database on
file system which runs without a separate process. I was originally writing the
vector db core myself to learn more of Rust, but then stopped doing that since
lancedb gives all that I needed, out of the box.
To test that everything works reasonably, I tried making a semantic search
version of apropos-documentation command in Emacs. This
apropos-documentation-sem is simpler in that does semantic search only on
function (not variable) documentations from symbols in obarray. To do this,
firstly we need to set up a store for vectors and push all the symbols with
documentation there:
(require 'apropos) (require 'sem) (require 'sem-embed) (defvar apropos-sem-documentation-store "apropos" "Name of the database for storing documentation.") (sem-store-new apropos-sem-documentation-store sem-embed-dim) (setq store (sem-store-load apropos-sem-documentation-store)) (let ((batch-size 50) (batch)) (mapatoms (lambda (symbol) (when-let ((doc (apropos-safe-documentation symbol))) (push (cons symbol doc) batch)) (when (= batch-size (length batch)) (sem-add-batch store batch #'sem-embed-default) (setq batch nil)))) ;; Store unaligned leftovers (when batch (sem-add-batch store batch #'sem-embed-default)))
This takes a bit of time (~ 20 mins on my machine: HP Spectre X360 11th Gen
Intel Evo Core i5). There is some extra vector copying involved here right now
which will go away in later versions.
Searching over these vectors (running #'sem-items-count gives me 38,171) is
pretty fast though.
(defun benchmark-sem () (let ((n-runs 10)) (format "%f seconds / query" (/ (car (benchmark-run n-runs (sem-similar store "testing" 5 (lambda (it) (aref (sem-embed-default (list (prin1-to-string it))) 0))))) n-runs)))) (benchmark-sem)
0.089578 seconds / query
You can always build an index (IVF-PQ index by default) over the vectors to speed this up even further at the cost of some accuracy.
(sem-build-index store) (benchmark-sem)
0.032963 seconds / query
Now we can run searches and produce output like any other apropos command:
(defun apropos-documentation-sem (search-phrase &optional k) "Search function docstrings (and name) using semantic search on SEARCH-PHRASE. Return top K results." (interactive "sSearch phrase: ") (let* ((results (sem-similar store search-phrase (or k 10) (lambda (it) (aref (sem-embed-default (list (prin1-to-string it))) 0)))) (apropos-accumulator (mapcar (lambda (res) (list (cadr res) (car res) (cddr res) nil)) results))) (apropos-print nil "\n----------------\n" (format "Semantic search results for: %s" search-phrase) t)))
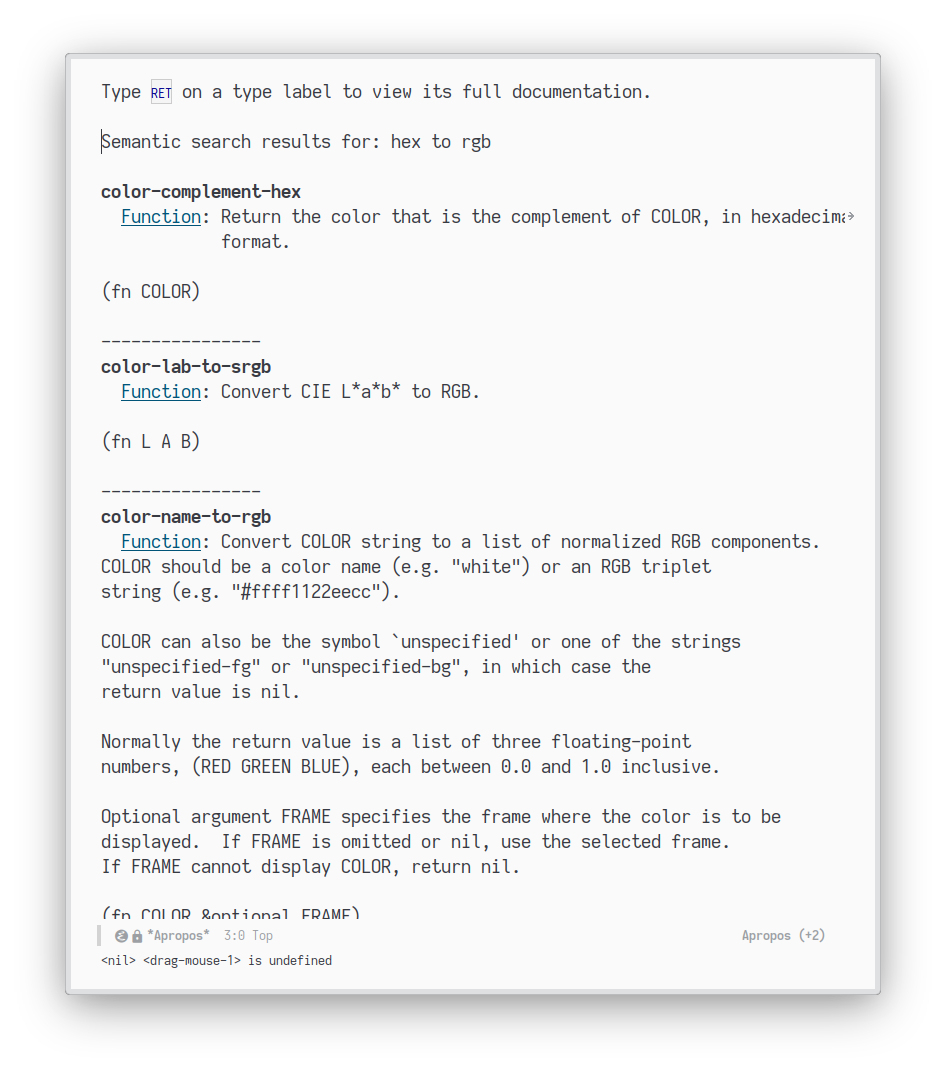
While searching over symbol documentation is a good test—since Emacs obarray is a realistic workload with a healthy amount of items—I do not think semantic search is helpful here. Most of my documentation searches have been better served with regular full string search since I already know the starting point which could be another function name, a module, etc. providing me with partial words.
My primary motivation is to put semantic search to use in my note taking system and that will drive any further development here. In any case, what follows is the setup code and config if you also want to do semantic searches within Emacs.
;; This needs cargo installed (use-package tokenizers :vc (:fetcher github :repo lepisma/tokenizers.el) :demand t) ;; This needs onnnxruntime development library installed on your system (use-package onnx :vc (:fetcher github :repo lepisma/onnx.el) :demand t) (use-package sem :vc (:fetcher github :repo lepisma/sem.el) :demand t :config ;; Create database directory (setq sem-database-dir (expand-file-name (concat user-emacs-directory "sem/"))) (make-directory sem-database-dir t) ;; Setup default text embedding model (setq sem-embed-model-path (concat sem-database-dir "model_O2.onnx")) (unless (file-exists-p sem-embed-model-path) (message "Model missing for sem-embed, downloading...") (url-copy-file "https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2/resolve/main/onnx/model_O2.onnx?download=true" sem-embed-model-path)))
The installation takes care of compilation as a blocking call which might be
slow, specially for sem. There are also a few rough edges around some database
operations which I will fix as needed.
With ONNX.el you can run any ML model inside Emacs, including ones for images, audios, etc. In case you are running embedding models, combine this with sem.el to perform semantic searches. Depending on your input modality, you might have to figure out preprocessing. For text, tokenizers.el should cover all of what you need in modern NLP for preprocessing, though you will have to do something on your own for anything non-text or multimodal.