This contains notes for paper-ish documents that I read.
1. Evolution/Complexity
1.1. READ Networks and history
CUSTOM_ID: bearman2002networks YEAR: 2002 AUTHOR: Bearman, Peter and Moody, James and Faris, Robert
This was a really nice read. I suspect it's not that nice for insiders though. Anyway, this presents a way to create case (in social sciences, a group of interconnected events specifying causalities of some sort) using a few tricks from network science.
Something a little counter intuitive for me was this idea that only robust nets (let's coin a better term) are important since they carry on and are the only meaningful things when you look back. I don't know enough but probably there are two ways of looking at something like a historical event.
- What actually happened. I believe happenstances play roles here but shouldn't drive derivations of general rules of thumb.
- What happens, taken out as a general, most probable (?), rule. The paper focuses on this piece by presenting ways of finding non chancy causes of events.
The problem is, I don't know which is more important to know about.
1.2. READ The causes of evolvability and their evolution
CUSTOM_ID: payne2018causes YEAR: 2018 AUTHOR: Payne, Joshua L and Wagner, Andreas
A very recent review on the subject with a bunch of experimental results. It talks about three "major causes of evolvability":
- Phenotype heterogeneity
- Robustness
- Adaptive landscapes
And
Whether they often evolve because they confer evolvability remains a particularly challenging open question.
1.3. READ Is evolvability evolvable?
CUSTOM_ID: pigliucci2008evolvability YEAR: 2008 AUTHOR: Pigliucci, Massimo
Barring for the various definitions of evolvability, we look at evolvability as some sort of hyperparametrically derived quantity. These hyperparameters define the phylogenic space the search will continue on in the future, therefore there are the usual two arguments for evolution of evolability in the selection setting:
- as a side effect
- targeted (sliding towards teleology)
Since this is a survey/opinion, there are not much technicalities here.
1.4. READ Robustness and evolvability: a paradox resolved
CUSTOM_ID: wagner2007robustness YEAR: 2007 AUTHOR: Wagner, Andreas
Here we put up definitions for robustness and evolvability for sequences (genotype) and structures (phenotype). The main conclusion says that these two values are negatively correlated for genotype, but they support each other in case of phenotype. There are a few quantitative results on the setting of RNA sequences and the structures they form.
The question I am interested in is, how much can this be generalized to arbitrary levels in arbitrary systems? The key property needed to get this working is:
…even though structure robustness increases modestly with structure frequency, this increase is much smaller than the vast increase in the number of different structures accessible found near a much larger neutral network.
which gives
…the populations with the highly robust phenotype are more diverse, and this increased diversity is much greater than the decreased diversity around any one sequence.
1.5. READ Robustness and evolvability
CUSTOM_ID: masel2010robustness YEAR: 2010 AUTHOR: Masel, Joanna and Trotter, Meredith V
A kind of review of the ideas behind evolutionary robustness. I got a few pointers and terminology to follow from this paper.
1.6. READ How learning can guide evolution
CUSTOM_ID: hinton1987learning YEAR: 1987 AUTHOR: Hinton, Geoffrey E and Nowlan, Steven J
Simulation of a minimalistic system for explaining the idea behind the searching power of evolution + learning. Look here for an argument against the specific example taken.
1.7. READ Coevolution to the edge of chaos: coupled fitness landscapes, poised states, and coevolutionary avalanches
CUSTOM_ID: kauffman1991coevolution YEAR: 1991 AUTHOR: Kauffman, Stuart A and Johnsen, Sonke
This one uses the NK model to experiment with coevolution. The main idea is that you can couple one NK landscape to another using a factor similar to K, called C, which defines how much the other affects this guy. Sounds like a reasonable model to represent the essence of coevolving species. An important hint that we get is that if a metadynamics is present to select the value of K, then that moves it to an attractor state where changes in the system cause avalanches resembling the sandpile model from bak1988self.
1.8. READ Computation at the edge of chaos: phase transitions and emergent computation
Custom_ID: langton1990computation AUTHOR: Langton JOURNAL: Physica D: Nonlinear Phenomena YEAR: 1990 VOLUME: 42 PAGES: 12--37
The question here focuses on how to get rules capable of computation in CAs. Specifically, we are looking at environments which characterize rules that allow:
- Storage of information
- Transmission
- Interaction between the above two
Intuitively, as the rule's output entropy increases, we move from a very simple output (more storage) to output with randomness (more transmission). In between these two, lies the region with the right amount of signal and noise with very large transients and this is where most of the interesting events take place.
An interesting idea involves the definition of \(\lambda\) parameter (that helps in categorizing the rules) which is basically a discrete probability distribution for the range of mapping function.
1.9. Self-organized criticality
Custom_ID: bak1988self AUTHOR: Bak, Tang \& Wiesenfeld JOURNAL: Physical review A YEAR: 1988 VOLUME: 38 PAGES: 364
1.10. READ Revisiting the edge of chaos: Evolving cellular automata to perform computations
Custom_ID: mitchell1993revisiting AUTHOR: Mitchell, Hraber \& Crutchfield JOURNAL: arXiv preprint adap-org/9303003 YEAR: 1993
The edge of chaos idea is pretty popular and used to explain many phenomena. A short article criticizing that is here. This is one of the papers that tried to debunk (kind of) an experiment (packard1988adaptation; this was in my reading list for a long time) which claimed that evolving (in the GA sense) a CA to solve computational problems gyrate it towards the edge of chaos.
It's pretty easy to see the issue since a solution to a specific problem (they took majority classification) is going to have a specific λ and that's going to be what that is, in spite of where the critical λ lies.
Other than that, this paper has some nice explanations and insights for the results from GA. One neat trick that I haven't seen much (though I haven't seen much) is of keeping the number of elites high and changing the evaluation function on each generation. This looks like a more practical way to use GAs in evaluation over real data set. I also like the trick where you stop at a variable number of generations to avoid getting a rule which gets the right answer by alternating between 0s and 1s.
1.11. READ Optimization by Self-Organized Criticality
Custom_ID: hoffmann2018optimization AUTHOR: Hoffmann \& Payton JOURNAL: Scientific reports YEAR: 2018 VOLUME: 8 PAGES: 2358
I believe it is not using SoC in the strict sense. The key is the generation of test patterns. Using the sandpile model, we get a reasonable exploration/exploitation trade offs. Also, two avalanches are less likely to occur on overlapping patches (I am going by hunches on this so can be wrong) so it also provides a more coordinate descent-ish behavior than the regular random patch thing. Not sure if we can say that SoC is specifically helping here.
There are two things. First is that this is better than the random approach (consider random patch since only that is fairly comparable). This probably needs a lot more test cases or some theoretical justification.
Second is about the optimality of the sandpile approach. How about other non 1/f
distributions? I don't know which generating mechanisms can be employed to get
the test patterns but fishing around a bit tells me that this purity of
distribution is not that justified (consider for example the recent
broido2018scale). The point being: if you fix an annealing schedule for
stimulated annealing based on some natural observation, that doesn't:
- create a parameter-less solver, and
- justify the natural observation to be the optimal
All said, I liked the thought of a random object (?) generator which does better than the regular approach in the general case. If there indeed is such a generator, this could work as an off-the-shelf technique replacing uniform random search.
1.12. At the edge of chaos: Real-time computations and self-organized criticality in recurrent neural networks
Custom_ID: bertschinger2005edge AUTHOR: Bertschinger, Natschl\"ager \& Legenstein JOURNAL: YEAR: 2005 PAGES: 145--152
2. Speech
2.1. READ Three Recent Trends in Paralinguistics on the Way to Omniscient Machine Intelligence
CUSTOM_ID: schuller2018three KEYWORDS: paralinguistics DATE: 2018-12-01 AUTHOR: Schuller, Björn W. and Zhang, Yue and Weninger, Felix
- Large scale data collection and automated annotations. This covers unsupervised and semi-supervised tracks.
- Deep and representational learning.
- Multi-modality and multi-task learning.
2.2. READ Is Spoken Language All-or-Nothing? Implications for Future Speech-Based Human-Machine Interaction
CUSTOM_ID: moore2017spoken KEYWORDS: slu DATE: 2017 AUTHOR: Moore, Roger K.
Habitability gap in speech systems. The argument is that because of the missing context and many other things, there is no such thing as half a language.
2.3. READ Conversational End-to-End TTS for Voice Agents
CUSTOM_ID: guo2021conversational YEAR: 2021 AUTHOR: Guo, Haohan and Zhang, Shaofei and Soong, Frank K and He, Lei and Xie, Lei
Two key ideas:
- Collect data by letting people play out scripts and further transcribe to fix and add spontaneous acts.
- Pass the conversational context (text) to the model while training.
2.4. READ The Zero Resource Speech Challenge 2020: Discovering discrete subword and word units
CUSTOM_ID: dunbar2020zero YEAR: 2020 AUTHOR: Dunbar, Ewan and Karadayi, Julien and Bernard, Mathieu and Cao, Xuan-Nga and Algayres, Robin and Ondel, Lucas and Besacier, Laurent and Sakti, Sakriani and Dupoux, Emmanuel
2.5. READ Word Error Rate Estimation Without ASR Output: e-WER2
CUSTOM_ID: ali2020word YEAR: 2020 AUTHOR: Ali, Ahmed and Renals, Steve
2.6. READ Conformer: Convolution-augmented Transformer for Speech Recognition
CUSTOM_ID: gulati2020conformer YEAR: 2020 AUTHOR: Gulati, Anmol and Qin, James and Chiu, Chung-Cheng and Parmar, Niki and Zhang, Yu and Yu, Jiahui and Han, Wei and Wang, Shibo and Zhang, Zhengdong and Wu, Yonghui and others
2.7. READ Streaming end-to-end bilingual ASR systems with joint language identification
CUSTOM_ID: punjabi2020streaming
YEAR: 2020
AUTHOR: Punjabi, Surabhi and Arsikere, Harish and Raeesy, Zeynab and Chandak, Chander and Bhave, Nikhil and Bansal, Ankish and M{\"u}ller, Markus and Murillo, Sergio and Rastrow, Ariya and Garimella, Sri and others
2.8. READ How to Annotate 100 Hours in 45 Minutes.
CUSTOM_ID: fallgren2019annotate YEAR: 2019 AUTHOR: Fallgren, Per and Malisz, Zofia and Edlund, Jens
2.9. READ An investigation of deep neural network architectures for language recognition in indian languages.
CUSTOM_ID: mounika2016investigation YEAR: 2016 AUTHOR: Mounika, KV and Achanta, Sivanand and Lakshmi, HR and Gangashetty, Suryakanth V and Vuppala, Anil Kumar
2.10. READ LibriTTS: A corpus derived from librispeech for text-to-speech
CUSTOM_ID: zen2019libritts YEAR: 2019 AUTHOR: Zen, Heiga and Dang, Viet and Clark, Rob and Zhang, Yu and Weiss, Ron J and Jia, Ye and Chen, Zhifeng and Wu, Yonghui
2.11. READ Convolutional neural networks for small-footprint keyword spotting
CUSTOM_ID: sainath2015convolutional YEAR: 2015 AUTHOR: Sainath, Tara N and Parada, Carolina
2.12. READ Small-footprint keyword spotting using deep neural networks
CUSTOM_ID: chen2014small YEAR: 2014 AUTHOR: Chen, Guoguo and Parada, Carolina and Heigold, Georg
2.13. READ Practical Application of Domain Dependent Confidence Measurement for Spoken Language Understanding Systems
CUSTOM_ID: mehrabani2018practical YEAR: 2018 AUTHOR: Mehrabani, Mahnoosh and Thomson, David and Stern, Benjamin
Tag noisy data and learn reject. Call center-ish use case.
2.14. READ Audio adversarial examples: Targeted attacks on speech-to-text
CUSTOM_ID: carlini2018audio YEAR: 2018 AUTHOR: Carlini, Nicholas and Wagner, David
2.15. READ Natural tts synthesis by conditioning wavenet on mel spectrogram predictions
CUSTOM_ID: shen2018natural YEAR: 2018 AUTHOR: Shen, Jonathan and Pang, Ruoming and Weiss, Ron J and Schuster, Mike and Jaitly, Navdeep and Yang, Zongheng and Chen, Zhifeng and Zhang, Yu and Wang, Yuxuan and Skerrv-Ryan, Rj and others
2.16. READ Dialog Methods for Improved Alphanumeric String Capture
CUSTOM_ID: peters2011dialog YEAR: 2011 AUTHOR: Peters, Doug and Stubley, Peter
Presents a way for dialog level collection of alpha numeric strings via an ASR. Two main ideas:
- Skip listing over n-best hypothesis across turns (attempts)
- Chunking and confirming pieces one by one
2.17. READ Deep Learning-Based Telephony Speech Recognition in the Wild.
CUSTOM_ID: han2017deep
YEAR: 2017
AUTHOR: Kyu J. {Han} and Seongjun {Hahm} and Byung-Hak {Kim} and Jungsuk {Kim} and Ian R. {Lane}
Details on CAPIO's call transcription system for 'in the Wild' data. A few nice bits of practical information if you are working on something similar. Specially the one about adaptation where even 10h of data gave them 5 percent point jump (base trained on switchboard) on real data.
2.18. READ SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition.
CUSTOM_ID: zoph2019specaugment
YEAR: 2019
AUTHOR: Barret {Zoph} and Chung-Cheng {Chiu} and Daniel S. {Park} and Ekin Dogus {Cubuk} and Quoc V. {Le} and William {Chan} and Yu {Zhang}
From the abstract:
The augmentation policy consists of warping the features, masking blocks of frequency channels, and masking blocks of time steps.
Kaldi has this supported as a layer (applied on spectrograms) in it's nnet3 framework.
2.19. READ Phoneme Level Language Models for Sequence Based Low Resource ASR
CUSTOM_ID: dalmia2019phoneme
YEAR: 2019
AUTHOR: Siddharth {Dalmia} and Xinjian {Li} and Alan W {Black} and Florian {Metze}
They try using a phoneme language model (PLM) for speech recognition decoding. There are two important pieces here. They train a single multilingual PLM (mapping all languages to IPA) and find it doing good across languages (from Babel dataset). Then they plug this in a CTC style model for decoding and find that doing better than CLM (character LM) and WFST (I am assuming this is an LG.fst) in low data setting.
2.20. READ Bootstrap estimates for confidence intervals in ASR performance evaluation
CUSTOM_ID: bisani2004bootstrap
YEAR: 2004
AUTHOR: M. {Bisani} and H. {Ney}
The idea used in compute-wer-bootci. Useful for comparing modifications in speech systems when the deltas are not convincingly different.
2.21. READ Speaker diarization with lstm
CUSTOM_ID: wang2018speaker YEAR: 2018 AUTHOR: Wang, Quan and Downey, Carlton and Wan, Li and Mansfield, Philip Andrew and Moreno, Ignacio Lopz
d-vector + spectral clustering.
2.22. READ Utterance-level Aggregation for Speaker Recognition in the Wild
CUSTOM_ID: xie2019utterance YEAR: 2019 AUTHOR: Xie, Weidi and Nagrani, Arsha and Chung, Joon Son and Zisserman, Andrew
Approached from more of a background reading perspective. Main idea is to use NetVLAD, GhostVLAD style (don't know much about these at the moment) aggregation across time instead of regular temporal average pooling.
2.23. READ pyannote.metrics: A Toolkit for Reproducible Evaluation, Diagnostic, and Error Analysis of Speaker Diarization Systems.
CUSTOM_ID: bredin2017pyannote
YEAR: 2017
AUTHOR: Hervé {Bredin}
Useful read for knowing metrics used in segmentation and diarization.
2.24. READ Fully Supervised Speaker Diarization
CUSTOM_ID: zhang2018fully
YEAR: 2018
AUTHOR: Aonan {Zhang} and Quan {Wang} and Zhenyao {Zhu} and John {Paisley} and Chong {Wang}
A relatively recent work which has two benefits:
- Allows unspecified number of speakers in an audio
- Learns the clustering over speaker embeddings in a supervised way
I am not totally clear on the parameter estimation part during my first pass but the code, which is here, should help.
2.25. READ Diarization is Hard: Some Experiences and Lessons Learned for the JHU Team in the Inaugural DIHARD Challenge.
CUSTOM_ID: sell2018diarization
YEAR: 2018
AUTHOR: Sell, Gregory and Snyder, David and McCree, Alan and Garcia-Romero, Daniel and Villalba, Jes{\'u}s and Maciejewski, Matthew and Manohar, Vimal and Dehak, Najim and Povey, Daniel and Watanabe, Shinji and others
I have been looking over this to get started and know about diarization a bit. Although I got a few concepts and terminologies, this assumes you already know your way around. There are probably better pieces if you want to clear up the basics. Here is a nice resource by the way.
2.26. READ Towards end-to-end spoken language understanding
CUSTOM_ID: serdyuk2018towards YEAR: 2018 AUTHOR: Serdyuk, Dmitriy and Wang, Yongqiang and Fuegen, Christian and Kumar, Anuj and Liu, Baiyang and Bengio, Yoshua
Simple results (plain intent-ish classification) on going directly from audio features to intent. An important decision, I believe, is to have bigger semantic chunks to recur on since audio is very sample heavy.
2.27. READ wav2vec: Unsupervised Pre-training for Speech Recognition.
CUSTOM_ID: schneider2019wav2vec
YEAR: 2019
AUTHOR: Steffen {Schneider} and Alexei {Baevski} and Ronan {Collobert} and Michael {Auli}
Not exactly what I assumed an x2vec would be with x = audio. Anyway, the idea is to have a language model-ish system for audio frames which acts as the featurizer for downstream tasks like, here, speech recognition. The gains are decent. There are a few good points covered in between which drive decisions while working with audio. Though I wonder what were the reasons for not going with spectrums1 if they are replacing log-mel input in regular speech recognizer.
2.28. READ Generalized end-to-end loss for speaker verification
CUSTOM_ID: wan2018generalized YEAR: 2018 AUTHOR: Wan, Li and Wang, Quan and Papir, Alan and Moreno, Ignacio Lopez
Leaving the speaker verification part aside, this presents a way to train embeddings with membership constraints so that items for one identity are grouped together and are easy to separate from the rest.
2.29. READ Transfer learning from speaker verification to multispeaker text-to-speech synthesis
CUSTOM_ID: jia2018transfer YEAR: 2018 AUTHOR: Jia, Ye and Zhang, Yu and Weiss, Ron and Wang, Quan and Shen, Jonathan and Ren, Fei and Nguyen, Patrick and Pang, Ruoming and Moreno, Ignacio Lopez and Wu, Yonghui and others
Real-Time-Voice-Cloning project pointed me here. Since I don't know much about speech synthesis at the moment, this also was a nice intro to the current modular breakdown. Three components are involved here:
- Discriminative speaker encoder. Trained on US English search voice data.
- Synthesizer. Takes text to spectrogram, conditioned on speaker encoding.
- Vocoder. Takes spectrograms to audio. Wavenet based.
2.30. READ Who needs words? lexicon-free speech recognition
CUSTOM_ID: likhomanenko2019needs YEAR: 2019 AUTHOR: Likhomanenko, Tatiana and Synnaeve, Gabriel and Collobert, Ronan
Took it from the wav2letter++ repo. Nothing very specific to comment on. Mostly a results paper. I like how well ConvLM does though.
2.31. READ wav2letter++: The fastest open-source speech recognition system
CUSTOM_ID: pratap2018wav2letter YEAR: 2018 AUTHOR: Pratap, Vineel and Hannun, Awni and Xu, Qiantong and Cai, Jeff and Kahn, Jacob and Synnaeve, Gabriel and Liptchinsky, Vitaliy and Collobert, Ronan
Although it might not be as friendly, I like the focus on architecture and types based guarantees in general. Kaldi just feels annoying at times.
2.32. READ Snips voice platform: an embedded spoken language understanding system for private-by-design voice interfaces
CUSTOM_ID: coucke2018snips
YEAR: 2018
AUTHOR: Coucke, Alice and Saade, Alaa and Ball, Adrien and Bluche, Th{\'e}odore and Caulier, Alexandre and Leroy, David and Doumouro, Cl{\'e}ment and Gisselbrecht, Thibault and Caltagirone, Francesco and Lavril, Thibaut and others
Document on how snips does their SLU in general. A nice thing that I didn't expect was focus on the dynamic LM part. It makes sense to make updates easy and quick on-premise as compared to keeping things mostly frozen.
2.33. READ Entity-Aware Language Model as an Unsupervised Reranker
CUSTOM_ID: rasooli2018entity YEAR: 2018 AUTHOR: Rasooli, Mohammad Sadegh and Parthasarathy, Sarangarajan
A few nice ideas. One was to autogenerate n-best list for a certain true text using phonetic similarity and subsequent LM reranking. Overall idea is to somehow introduce the relation between potential entities in the text while ranking alternatives. The exact approach looks a little too much and I would like to know more about how and why the decisions were taken even though whatever they did sounds intuitive. Backstories people.
2.34. READ Parallelizing wfst speech decoders
CUSTOM_ID: mendis2016parallelizing YEAR: 2016 AUTHOR: Mendis, Charith and Droppo, Jasha and Maleki, Saeed and Musuvathi, Madanlal and Mytkowicz, Todd and Zweig, Geoffrey
I didn't get everything here mostly because of the split between AM and LM phase. Will probably look over with more background. Overall, the idea is to parallelize viterbi as you would think but keeping inter thread communication very low by clumping actions which are mostly independent given their thread's other actions. This clumping gains by knowledge of the graph structure which is affected by the domain; in this case using the information about triphones.
2.35. READ Comparison of grapheme-to-phoneme methods on large pronunciation dictionaries and LVCSR tasks
CUSTOM_ID: hahn2012comparison YEAR: 2012 AUTHOR: Hahn, Stefan and Vozila, Paul and Bisani, Maximilian
This is mostly a comparison of statistical g2p models. I think I have a general idea now but looks like there is a lot more to see if I start looking into individual references. A general thread along all these models was the use of a certain alignment (grapheme to phoneme) algorithm to get what are called graphones and then train an ngrams-ish sequence model on them.
2.36. READ Statistical language modeling for speech disfluencies
CUSTOM_ID: stolcke1996statistical YEAR: 1996 AUTHOR: Stolcke, Andreas and Shriberg, Elizabeth
Got here from srilm's disfluency (DF) LM. The idea is to have a cleanup model which models out certain common DFs, specifically filled pauses, repetitions and deletions. Although there was not much gain, an interesting conclusion comes with filled pauses where the DF model actually increased perplexity. The argument being a filled pause, in most of the cases, linguistically breaks the sentence and so the context behind it is not so useful for what follows.
Since the paper is old and also hints at a bunch of improvements in DF modeling, I guess there might be a more recent reference around.
2.37. READ Streaming End-to-end Speech Recognition For Mobile Devices
CUSTOM_ID: he2018streaming YEAR: 2018 AUTHOR: He, Yanzhang and Sainath, Tara N and Prabhavalkar, Rohit and McGraw, Ian and Alvarez, Raziel and Zhao, Ding and Rybach, David and Kannan, Anjuli and Wu, Yonghui and Pang, Ruoming and others
From Google's recent on-device character level Speech Recognition system. There are a bunch of tricks used in the overall system other than the main model itself. A few are:
- parameter quantization (required, of course, for fast computation on mobile device)
- data augmentation using tts for getting numbers, proper nouns etc. right (instead of doing fancy stuff on the model side)
2.38. Generating exact lattices in the WFST framework
CUSTOM_ID: povey2012generating
YEAR: 2012
AUTHOR: Povey, Daniel and Hannemann, Mirko and Boulianne, Gilles and Burget, Luk{\'a}{\v{s}} and Ghoshal, Arnab and Janda, Milo{\v{s}} and Karafi{\'a}t, Martin and Kombrink, Stefan and Motl{\'\i}{\v{c}}ek, Petr and Qian, Yanmin and others
2.39. READ Quantifying the value of pronunciation lexicons for keyword search in lowresource languages
CUSTOM_ID: chen2013quantifying YEAR: 2013 AUTHOR: Chen, Guoguo and Khudanpur, Sanjeev and Povey, Daniel and Trmal, Jan and Yarowsky, David and Yilmaz, Oguz
In a single line, while pronunciation dictionary augmentation doesn't help that much in WER of an LVCSR (since the OOV rates are usually low), it helps a lot in Keyword Search.
A few other things to note are the ways to generate pronunciation and two ways to do KWS if you already have an LVCSR system. Not surprisingly, the proxy keyword system doesn't work that well.
2.40. READ State-of-the-art speech recognition with sequence-to-sequence models
CUSTOM_ID: chiu2018state YEAR: 2018 AUTHOR: Chiu, Chung-Cheng and Sainath, Tara N and Wu, Yonghui and Prabhavalkar, Rohit and Nguyen, Patrick and Chen, Zhifeng and Kannan, Anjuli and Weiss, Ron J and Rao, Kanishka and Gonina, Ekaterina and others
Bunch of improvements on top of the LAS architecture. It feels funny that even in end-to-end systems, we still look for modular presence of components like Language Models. Maybe that helps in adding and justifying heuristics.
2.41. Speech recognition with weighted finite-state transducers
CUSTOM_ID: mohri2008speech YEAR: 2008 AUTHOR: Mohri, Mehryar and Pereira, Fernando and Riley, Michael
Partial notes:
- Composition: Transitive-ness.
- Determinization: Removing multiple transitions on same input.
- Minimization: Compressing to the minimal, equivalent automaton. Done by first weight pushing and then running the classical algorithm.
3. Language
3.1. READ Optimizing dialogue management with reinforcement learning: Experiments with the NJFun system
CUSTOM_ID: singh2002optimizing YEAR: 2002 AUTHOR: Singh, Satinder and Litman, Diane and Kearns, Michael and Walker, Marilyn
Early use of RL (MDP) in dialog management. This is not about learning the actual conversational flow but few high level policies like confirmation, initiation, etc.
They show increase task completion rate with their learned policy. Main contribution is in the formulation of the problem including states, actions, and rewards.
3.2. READ Optimize the obvious: automatic call flow generation
CUSTOM_ID: suendermann2010optimize YEAR: 2010 AUTHOR: Suendermann, David and Liscombe, Jackson and Pieraccini, Roberto
Building flow of questions based on entropy reduction.
3.3. READ What makes a good conversation? how controllable attributes affect human judgments
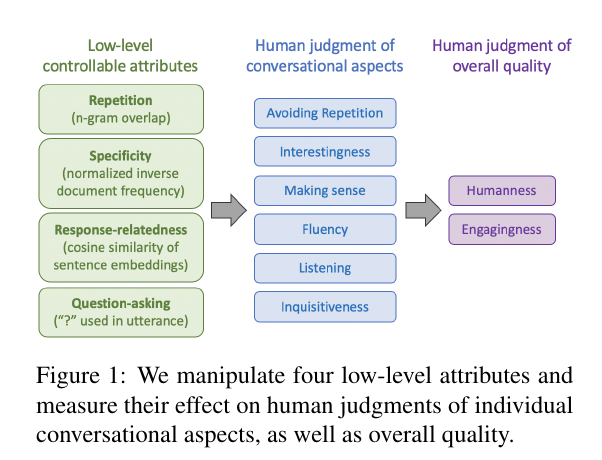
CUSTOM_ID: see2019makes YEAR: 2019 AUTHOR: See, Abigail and Roller, Stephen and Kiela, Douwe and Weston, Jason
The following image summarizes the paper's approach:
3.4. READ Towards a human-like open-domain chatbot
CUSTOM_ID: adiwardana2020towards YEAR: 2020 AUTHOR: Adiwardana, Daniel and Luong, Minh-Thang and So, David R and Hall, Jamie and Fiedel, Noah and Thoppilan, Romal and Yang, Zi and Kulshreshtha, Apoorv and Nemade, Gaurav and Lu, Yifeng and others
Meena paper. I like the idea of measuring Sensibleness and Specificity as metrics for evaluation of dialogs in terms of human likeness.
3.5. READ Beyond accuracy: Behavioral testing of NLP models with CheckList
CUSTOM_ID: ribeiro2020beyond YEAR: 2020 AUTHOR: Ribeiro, Marco Tulio and Wu, Tongshuang and Guestrin, Carlos and Singh, Sameer
More metrics that also cover various aspects of different capabilities. This is an open source toolkit that has some approaches for assisting generation of test cases too.
3.6. READ PARADISE: A framework for evaluating spoken dialogue agents
CUSTOM_ID: walker1997paradise YEAR: 1997 AUTHOR: Walker, Marilyn A and Litman, Diane J and Kamm, Candace A and Abella, Alicia
General point to use a metric for task success (they use kappa over all possible parse-ables in the situation) and separate metrics for dialog costs (things like number of turns, number of repairs, etc.) and run regression from here to predict CSAT like scores. Once this model is learnt, this is used later on without relying on tagging CSAT. The regression weights also give insight in what is impacting CSAT in what way.
Another key idea was to tag turns using a technique that makes it easy to extract subdialogs which themselves are score-able on the same scales as above. This makes it easy to know what is going wrong (e.g. which entity parsing strategy is screwing up) and how to compare two strategies for the same goal.
3.7. READ Real conversations with artificial intelligence: A comparison between human–human online conversations and human–chatbot conversations
CUSTOM_ID: hill2015real YEAR: 2015 AUTHOR: Hill, Jennifer and Ford, W Randolph and Farreras, Ingrid G
The most reasonable explanation for this finding – combined with the unexpected finding of greater messages to chatbots – seems to be not that people were tentative in their communication with chatbots, but rather that they were modeling their communication to match that of the chatbot’s, in the same way that people adapt their language when conversing with children (Bloom, Rocissano, & Hood, 1976; Hausendorf, 1992) or non-native speakers (Ferguson, 1975).
We can and should do a similar analysis with voice conversations. Since ours are goal oriented systems, we can define a different set of factors to compare. Few examples:
- Non-standard queries asked. Even if the goal is to book a table, with a bot, we might see less deviations from a script and more with humans.
- General conversation metrics like words per utterance, intents per utterance, number of utterances, etc.
- Voice conversation specific metrics like interjections, acknowledgements, etc.
This should be doable on deployments where we have human-human and human-bot data.
I also feel doing this kind of analysis is a way of knowing current state our systems. If we really are human-like, then there will be no difference (except when we declare that "you are talking to an automated assistant"). This analysis might give us better metrics and pathways for building more human like systems.
3.8. READ ST-BERT: Cross-modal Language Model Pre-training For End-to-end Spoken Language Understanding
CUSTOM_ID: kim2020st YEAR: 2020 AUTHOR: Kim, Minjeong and Kim, Gyuwan and Lee, Sang-Woo and Ha, Jung-Woo
3.9. READ FastFormers: Highly Efficient Transformer Models for Natural Language Understanding
CUSTOM_ID: kim2020fastformers YEAR: 2020 AUTHOR: Kim, Young Jin and Awadalla, Hany Hassan
3.10. READ On the Cross-lingual Transferability of Monolingual Representations
CUSTOM_ID: mikel2019cross YEAR: 2019 AUTHOR: Mikel Artetxe and Sebastian Ruder and Dani Yogatama
- The idea of learning embeddings to fit in with a set of layers trained for another language can mostly be used in other kinds of models too.
- There was an interesting degradation in Hindi (+ Turkey) with positional embedding on XQuAD (recoverable with added adapters). I am wondering whether this is because
transferring syntactic abstractions is more challenging than semantic abstractions.
3.11. READ Distributed representations of sentences and documents
CUSTOM_ID: le2014distributed YEAR: 2014 AUTHOR: Le, Quoc and Mikolov, Tomas
Document vectorization paper following the general series of word2vec ones.
3.12. READ Mixing dirichlet topic models and word embeddings to make lda2vec
CUSTOM_ID: moody2016mixing YEAR: 2016 AUTHOR: Moody, Christopher E
While I like the results, I am wondering which pieces were useful, which were not and how do things compare to other techniques.
3.13. READ Probing Neural Network Comprehension of Natural Language Arguments
CUSTOM_ID: niven2019probing YEAR: 2019 AUTHOR: Niven, Timothy and Kao, Hung-Yu
Was up on r/ml. The abstract is short and clear enough. The idea is that ARCT tasks have simple statistical cues which contribute in a major way for whatever SOTA we are getting. One you balance them out, even strong models like BERT take big hits and go to essentially random-ish performance.
3.14. READ Alignment in dialogue
CUSTOM_ID: garrod2007alignment YEAR: 2007 AUTHOR: Garrod, Simon and Pickering, Martin J
Picked up this because I wanted to get general background of alignment as a linguistic term. A few points I pulled out:
- Common ground (stuff believed to be shared) is stricter than alignment which only refers to the information that happens to be shared.
- Ways of alignment:
- via beliefs about one's interlocutor
- via imitation
- via agreements between interlocutors
- via feedback
- via physical co-presence
3.15. READ Statistical user simulation with a hidden agenda
CUSTOM_ID: schatzmann2007statistical YEAR: 2007 AUTHOR: Schatzmann, Jost and Thomson, Blaise and Young, Steve
This was pointed to by papangelis2019collaborative as a way of modeling users. Two good ideas here:
- Stack based agenda and the general decomposition of the process.
- Tractability piece where we try to put assumptions on various factors like transition probabilities etc.
3.16. READ Collaborative Multi-Agent Dialogue Model Training Via Reinforcement Learning
CUSTOM_ID: papangelis2019collaborative YEAR: 2019 AUTHOR: Papangelis, Alexandros and Wang, Yi-Chia and Molino, Piero and Tur, Gokhan
This is the paper which came out with Uber's plato's release. Here is what you need to know really:
Using DSTC2 as seed data, we trained NLU and NLG networks for each agent and let the agents interact and learn online optimal dialogue policies depending on their role (seeker or provider).
3.17. READ Building a conversational agent overnight with dialogue self-play
CUSTOM_ID: shah2018building
YEAR: 2018
AUTHOR: Shah, Pararth and Hakkani-T{\"u}r, Dilek and T{\"u}r, Gokhan and Rastogi, Abhinav and Bapna, Ankur and Nayak, Neha and Heck, Larry
Nice ideas in here plus insights for practical systems like the following,
Covering complex interactions is important when developing datasets to benchmark research aimed towards building human-level dialogue systems. However, we argue that for consumer-facing chatbots, the primary aim is reliable coverage of critical user interactions.
The generated dataset is here by the way.
3.18. READ Bootstrapping Conversational Agents With Weak Supervision
CUSTOM_ID: mallinar2018bootstrapping YEAR: 2018 AUTHOR: Mallinar, Neil and Shah, Abhishek and Ugrani, Rajendra and Gupta, Ayush and Gurusankar, Manikandan and Ho, Tin Kam and Liao, Q Vera and Zhang, Yunfeng and Bellamy, Rachel KE and Yates, Robert and others
I like there method of mass tagging. Other than that, this is a practical implementation of a snorkel like system.
3.19. READ Few-Shot Generalization Across Dialogue Tasks
CUSTOM_ID: vlasov2018few YEAR: 2018 AUTHOR: Vlasov, Vladimir and Drissner-Schmid, Akela and Nichol, Alan
The idea is to put all the involved pieces in a dialog, i.e. slots, intents and actions, in a space and then match with possible actions to do something. The key idea is to have the items break into compositional pieces before embedding so that a new domain can share along a lot of items and get along well.
3.20. READ Neural machine translation of rare words with subword units
CUSTOM_ID: sennrich2015neural YEAR: 2015 AUTHOR: Sennrich, Rico and Haddow, Barry and Birch, Alexandra
This is the application of subword (BPE based) on NMT. The results mostly show robustness and better learned handling of OOV stuff.
3.21. READ SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing
CUSTOM_ID: kudo2018sentencepiece YEAR: 2018 AUTHOR: Kudo, Taku and Richardson, John
A more rewarding read here can be the code in the repository itself since this is just a short documentation on the methods implemented.
3.22. READ Bpemb: Tokenization-free pre-trained subword embeddings in 275 languages
CUSTOM_ID: heinzerling2017bpemb YEAR: 2017 AUTHOR: Heinzerling, Benjamin and Strube, Michael
This is mostly a report on byte-pair embedding results and comparison with other models. Tracing back to (sennrich2015neural) and the original compression paper (gage1994new) should cover the background.
3.23. READ SRILM-an extensible language modeling toolkit
CUSTOM_ID: stolcke2002srilm YEAR: 2002 AUTHOR: Stolcke, Andreas
This is an early document on SRILM's design and development. If you are looking for something more in-depth, just download the current tarball.
3.24. READ A bit of progress in language modeling
CUSTOM_ID: goodman2001bit YEAR: 2001 AUTHOR: Goodman, Joshua T
This has a lot of nice ideas and intuitions behind tricks employed in statistical language models. I will just write out the general topics since it's a long paper (~73 pages for the extended version):
- Skipping
- Clustering
- Caching
- Sentence Mixture Models
At a higher level we get to know about:
- ways of combining
- approaching analysis
- practical issues
3.25. READ Rapidly building domain-specific entity-centric language models using semantic web knowledge sources
CUSTOM_ID: akbacak2014rapidly
YEAR: 2014
AUTHOR: Akbacak, Murat and Hakkani-T{\"u}r, Dilek and Tur, Gokhan
This is focused on filtering search queries for creating language model. The filtering that works out for them is to (after identifying a domain) go from queries to clicked links then back to queries that went to those links. There are a few other pieces involved but the general shape of narrowing is the same.
3.26. READ Gmail Smart Compose: Real-Time Assisted Writing
CUSTOM_ID: andrew2019gmail YEAR: 2019 AUTHOR: Andrew Dai and Benjamin Lee and Gagan Bansal and Jackie Tsay and Justin Lu and Mia Chen and Shuyuan Zhang and Tim Sohn and Yinan Wang and Yonghui Wu and Yuan Cao and Zhifeng Chen
3.27. READ Self-supervised dialogue learning
CUSTOM_ID: wu2019self YEAR: 2019 AUTHOR: Wu, Jiawei and Wang, Xin and Wang, William Yang
The self-supervision signal here is coming from a model which tries to predict whether a provided tuple of turns is in order or not. Connecting this as the discriminator in generative-discriminative dialog systems they find better results.
3.28. READ Learning from Dialogue after Deployment: Feed Yourself, Chatbot!
CUSTOM_ID: hancock2019learning YEAR: 2019 AUTHOR: Hancock, Braden and Bordes, Antoine and Mazare, Pierre-Emmanuel and Weston, Jason
This is an approach to collect supervision signal from deployment data. There are three tasks for the system (which is a chat bot doing ranking on candidate responses):
- Dialogue. The main task. Given the turns till now, the bot ranks which response to utter.
- Satisfaction. Given turns till now, last being user utterance, predict whether the user is satisfied.
- Feedback. After asking for feedback from the user, predict user's response (feedback) based on the turns till now.
The models have shared weights, mostly among task 1 and 3.
3.29. READ Learning language from a large (unannotated) corpus
CUSTOM_ID: vepstas2014learning YEAR: 2014 AUTHOR: Vepstas, Linas and Goertzel, Ben
Introductory paper on the general approach used in learn. The idea is to learn various generalizable syntactic and semantic relations from unannotated corpus. The relations are expressed using graphs sitting on top of link grammar and meaning text theory (MTT). While the general approach is sketched out decently enough, there are details to filled in various steps and experiments to run (as of the writing in 2014).
On another note, the document is a nice read because of the many interesting ways of looking at various ideas in understanding languages and going from syntax to reasoning via semantics.
3.30. READ Parsing English with a link grammar
CUSTOM_ID: sleator1995parsing YEAR: 1995 AUTHOR: Sleator, Daniel DK and Temperley, Davy
Came to here via opencog's learn project. I have a patchy information about formal grammars so this was also a nice perspective setup. Overall a link grammar defines connectors on left and right side of a word with disjunctions and conjunctions incorporated which then link together to form a sentence, under certain constraints.
This specific paper shows the formulation and creates a parser for English, covering many (not all) linguistics phenomena.
3.31. READ Learning to map sentences to logical form: Structured classification with probabilistic categorial grammars
CUSTOM_ID: zettlemoyer2012learning YEAR: 2012 AUTHOR: Zettlemoyer, Luke S and Collins, Michael
Assuming the title clarifies the goal, there are three basic components here:
- A parser which takes a sentence \(S\), a set of categories \(\Lambda\) and weights over features of the derivation (generated from parsing) \(\theta\). This then generates logical forms (\(L\)) with certain probabilities.
- Category generator which takes \(S\) and its expected logical form \(L\) to generate the categories needed to parse it to that form.
- An estimator which, given the training set and a set of categories, updates \(\theta\) to increase the score of the form getting parsed.
The interesting pieces are the representation of the logical form \(L\) (using λ calculus) and category generation and pruning. Although the generated categories can be arbitrary, allowing for wrong grammars and such, I believe, it can be made to work better in noisy settings if we generalize parsing and (maybe) the meaning of the structurally rigid categories like \(S/NP\) using a few tricks.
3.32. READ A very short introduction to CCG
CUSTOM_ID: steedman1996very YEAR: 1996 AUTHOR: Steedman, Mark
A lambda calculus formulation of verb (function) acts in natural text. Not sure if I can figure out exact advantages as compared to other approaches. This definitely has more appeal to it because of the functional forms and the tooling they pull in with themselves.
3.33. READ Swoosh: a generic approach to entity resolution
CUSTOM_ID: benjelloun2009swoosh YEAR: 2009 AUTHOR: Benjelloun, Omar and Garcia-Molina, Hector and Menestrina, David and Su, Qi and Whang, Steven Euijong and Widom, Jennifer
The main products are optimal algorithms to do ER which minimize the number of calls to the black box functions that actually perform the matching and merging. To do this, we first formalize the ER problem using:
- Records and features as the data structures
- Merging and matching functions as the operations
Then we look for certain properties of a particular setting (mostly the effect of merge and match functions). Based on whether a few of these are satisfied (surprisingly trivial functions might not do what you expect of them), we can reduce the number of calls to matching.
3.34. READ How not to evaluate your dialogue system: An empirical study of unsupervised evaluation metrics for dialogue response generation
CUSTOM_ID: liu2016not YEAR: 2016 AUTHOR: Liu, Chia-Wei and Lowe, Ryan and Serban, Iulian V and Noseworthy, Michael and Charlin, Laurent and Pineau, Joelle
Other than the usuals, it has decent summaries of a few metrics used for sentence similarity.
3.35. READ Bringing machine learning and compositional semantics together
CUSTOM_ID: liang2015bringing YEAR: 2015 AUTHOR: Liang, Percy and Potts, Christopher
Got pointed to this while going through sippycup. This presents, in a very pedagogical way, a simple framework for ranking semantic parses using supervised learning. The important point is that this framework can be applied to a lot of problems in nlu involving different ways of structuring the logical forms and features.
3.36. READ Abstract meaning representation for sembanking
CUSTOM_ID: banarescu2013abstract YEAR: 2013 AUTHOR: Banarescu, Laura and Bonial, Claire and Cai, Shu and Georgescu, Madalina and Griffitt, Kira and Hermjakob, Ulf and Knight, Kevin and Koehn, Philipp and Palmer, Martha and Schneider, Nathan
I found AMR while looking into a way of breaking from the usual intent/entity based NLU. While they are not perfect, the specification tells you about pieces which should (in elaborate situations) be considered at least for practical computational language understanding.
3.37. READ Bootstrapping language models for dialogue systems
CUSTOM_ID: weilhammer2006bootstrapping YEAR: 2006 AUTHOR: Weilhammer, Karl and Stuttle, Matthew N and Young, Steve
This is quickly getting domain specific LMs. The idea is to not do a lot of manual (and perfect) text collection but start with simple grammars and get a seed LM using the generated text. Then for more refinements, get a large LM and do sentence selection on in-the-wild data to get sentences with low value of \(PP_{seed} / PP_{large}\). These sentences and the rejected ones then give two more LMs which can then be interpolated based on a validation set.
Exact steps aside, the idea (other than SLMs on grammar generated data) is to do some sort of sentence selection to augment the seed LM.
3.38. READ Developing Production-Level Conversational Interfaces with Shallow Semantic Parsing
CUSTOM_ID: raghuvanshi2018developing YEAR: 2018 AUTHOR: Raghuvanshi, Arushi and Carroll, Lucien and Raghunathan, Karthik
Doc on Mindmeld's NLU system.
3.39. READ Neural text generation from structured data with application to the biography domain
CUSTOM_ID: lebret2016neural
YEAR: 2016
AUTHOR: Lebret, R{\'e}mi and Grangier, David and Auli, Michael
From wikipedia info entry (a table) for a person, they generate biographical sentences. The way to condition on the table while doing \(P(w_i | c_{(i-1)})\) is just indexing into (learnable) embeddings. I was looking for something more insightful though.
4. General AI/ML
4.1. READ Your Classifier is Secretly an Energy Based Model and You Should Treat it Like One
CUSTOM_ID: grathwohl2019classifier YEAR: 2019 AUTHOR: Will Grathwohl and Kuan-Chieh Wang and Jörn-Henrik Jacobsen and David Duvenaud and Mohammad Norouzi and Kevin Swersky
They take a regular classifier, pick out logits before softmax and try to formulate an energy based model able to give \(P(x, y)\) and \(P(x)\). The formulation itself is pretty simple with the energy function being \(E(x) = −LogSumExp_yf_\Theta(x)[y]\). Final loss sums cross entropy (for discriminative part) and negative log likelhood of \(P(x)\) approximated using SGLD. Check out the repo here.
Although the learning mechanism is a little fragile and needs work to be generally stable, the results are neat.
4.2. READ Snuba: automating weak supervision to label training data
CUSTOM_ID: varma2018snuba
YEAR: 2018
AUTHOR: Varma, Paroma and R{\'e}, Christopher
This is a logical extension of ratner2017snorkel. Instead of users writing heuristics, we go one level farther and just provide primitives (semantically meaningful feature chunks). There are three components:
- Synthesizer that does heuristic creation based on certain labelled dataset.
- A pruner that picks good heuristics, based on certain definitions and constraints.
- A verifier which closes the loop by deciding when to stop, what to feed to synthesizer etc.
While there are obvious upgrades in how we are doing everything, the general architecture reminds me much of classical rule learning systems like LCS.
4.3. READ One neuron is more informative than a deep neural network for aftershock pattern forecasting
CUSTOM_ID: mignan2019one YEAR: 2019 AUTHOR: Mignan, Arnaud and Broccardo, Marco
Got from r/MachineLearning. Title kind of says what is there in the paper. Even then, I would recommend skimming it just because the model is drastically simpler than the neural-net they are comparing to.
4.4. READ The Secret Sharer: Evaluating and testing unintended memorization in neural networks
CUSTOM_ID: carlini2019secret
YEAR: 2019
AUTHOR: Carlini, Nicholas and Liu, Chang and Erlingsson, {\'U}lfar and Kos, Jernej and Song, Dawn
This tries to formalize the problem of unintended memorization in neural networks. Notice the emphasis. There are many different ways to interpret memorization and the authors here are only concerned about cases where (say) something like a private sequence gets sucked in the memory and Mallory is able to extract such pieces with reasonable common attacks.
Important is their metric, called exposure, which kind of defines how easy it is to get a memorized piece of information out by playing around with the model API.
4.5. READ What’s your ML Test Score? A rubric for ML production systems
CUSTOM_ID: breck2016s YEAR: 2016 AUTHOR: Breck, Eric and Cai, Shanqing and Nielsen, Eric and Salib, Michael and Sculley, D
This is a good guide to follow if you work in a production ML setting.
4.6. READ Supervising strong learners by amplifying weak experts
CUSTOM_ID: christiano2018supervising YEAR: 2018 AUTHOR: Christiano, Paul and Shlegeris, Buck and Amodei, Dario
This is the Iterated Amplification paper. General idea is that harder problems can't be solved directly in a stable way so we want to use expert assistance for breaking down things in pieces. Then an interactive process lets the to-be trained system learn from both the ways things are broken and answer constructed. Since this is one of the initial works, the overall framework might change a little.
Simple algorithmic examples are provided. It will be interesting to see attempts towards the candidate problems which are beyond human intelligence. Haven't really followed the thread so don't know if there already is something done in this direction.
4.7. READ Frustratingly easy domain adaptation
CUSTOM_ID: daume2009frustratingly
YEAR: 2009
AUTHOR: Daum{\'e} III, Hal
Tells you how far good insights go. The paper is really simple to follow so not writing anything here.
4.8. READ Green AI
CUSTOM_ID: schwartz2019green YEAR: 2019 AUTHOR: Schwartz, Roy and Dodge, Jesse and Smith, Noah A. and Etzioni, Oren
A noble idea to push for.
I sometime feel bad that things which are good inherently, need to be pushed out in a gamified way for actions to be taken.
4.9. READ Bayesian learning via stochastic gradient Langevin dynamics
CUSTOM_ID: welling2011bayesian YEAR: 2011 AUTHOR: Welling, Max and Teh, Yee W
The update equation here is a minibatched SGD's with a normal noise factor \(\eta\):
\[ \Delta\theta_{t} = \frac{\epsilon_{t}}{2} \left(\nabla \log p (\theta_{t}) + \frac{N}{n} \sum_{i=1}^{n} \nabla \log p (x_{ti} | \theta_{t}) \right) + \eta_{t} \]
Main results involve showing that, when the rate \(\epsilon\) decays following certain properties, the noise due to minibatch dominates in the initial phase giving us normal SGD while the \(\eta\) noise dominates in the later phase which basically lets us sample from the posterior of \(\theta\).
The question of when to say we are in the sampling phase (so that we can start collecting samples, taking the SGD phase as burn-in) is also answered though I am missing some statistical tooling at the moment to appreciate it.
4.10. READ Learning by analogy: Formulating and generalizing plans from past experience
CUSTOM_ID: carbonell1983learning YEAR: 1983 AUTHOR: Carbonell, Jaime G
The summary overall is solving problems \(\equiv\) learning to solve problems. This is probably in general applicable to all analogy based methods but here the idea is also to apply learnings from one problem/domain to others. Two key components are involved here:
- Apply a generic problem solver (in the classical planning sense) to higher order problems like reducing a past solution to a new solution for another problem.
- A learning system which helps in learning parameters for a memory table which indexes actions based on the effects they produce.
Like in many older papers a lot of deliberations from here too are probably now parametrized and learned.
4.11. READ Large-Scale Long-Tailed Recognition in an Open World
CUSTOM_ID: liu2019large YEAR: 2019 AUTHOR: Liu, Ziwei and Miao, Zhongqi and Zhan, Xiaohang and Wang, Jiayun and Gong, Boqing and Yu, Stella X
Here we are grouping the following three tasks, their losses, metrics etc. in one:
- Regular (a little imbalanced) classification
- Few shot classification
- Out of Domain classification
Even though the system is a full network, there are planned components in there. Two are noteworthy:
- A distance metric, reachability in paper, goes to tell how different an instance is as compared to seen examples. This helps in task 2 vs 3.
- Memorized feature infusion which comes into picture in task 1 vs 2. Here we put more weights for features from a memory which helps in reducing the bias towards regular classes with large number of training samples.
4.12. READ Model-based testing without models: the TodoMVC case study
CUSTOM_ID: bainczyk2017model YEAR: 2017 AUTHOR: Bainczyk, Alexander and Schieweck, Alexander and Steffen, Bernhard and Howar, Falk
This is a case study of a general purpose UI testing approach. Here are the general steps:
- You define a set of actions that can be done.
- Learn a mealy model (makes sense for a lot of UIs) based on exploration using those states (I am not very sure I am using the correct phrasing for this learning)
- Compare with reference, among siblings etc. Probably also fuzz.
Even though there is not much in this specific paper itself, I got a general overview of the scene and references to a few primary sources.
4.13. READ Morphnet: Fast & simple resource-constrained structure learning of deep networks
CUSTOM_ID: gordon2018morphnet YEAR: 2018 AUTHOR: Gordon, Ariel and Eban, Elad and Nachum, Ofir and Chen, Bo and Wu, Hao and Yang, Tien-Ju and Choi, Edward
In a single line (from the appendix) what is happening is:
iterative process of shrinking via a sparsifying regularizer and expanding via a uniform multiplicative factor
The regularizer is an \(L1\) over the batch norm γ parameters for neurons.
4.14. READ Learning reductions that really work
CUSTOM_ID: beygelzimer2016learning
YEAR: 2016
AUTHOR: Beygelzimer, Alina and Daum{\'e}, Hal and Langford, John and Mineiro, Paul
I was looking into the general ideas behind Vowpal Wabbit and got to this document which probably summarizes the whole concept of learning reductions.
An important question is how general and fundamental this whole idea really is. Of course computational benefits are a major plus, but reductions also feel very elegant.
4.15. READ Unsupervised Grounding of Plannable First-Order Logic Representation from Images
CUSTOM_ID: asai2019unsupervised YEAR: 2019 AUTHOR: Asai, Masataro
This is a attempt to have interpretable representation from a neural network that can be used with planing systems. The abstract should tell you what problems are getting solved. The keys ideas are the following:
- First Order State Auto Encoder (FOSAE) where the latent space represents FOL predicates based on certain input objects and specified hyperparameters.
- Extensive use of Gumbel-Softmax to impose unitary credit assignment.
I am not very sure how different this is from similar recent works since I haven't followed them. But the main difference looks like focusing on discrete representations and planning capabilities of PDDL-ish tools. Interpretability comes as a side effect.
Since the predicates here are anonymous as of now, an interesting piece of future work involves a bit of supervision to put names on things.
4.16. READ Detecting spacecraft anomalies using lstms and nonparametric dynamic thresholding
CUSTOM_ID: hundman2018detecting YEAR: 2018 AUTHOR: Hundman, Kyle and Constantinou, Valentino and Laporte, Christopher and Colwell, Ian and Soderstrom, Tom
I picked this paper mostly randomly while looking around for the general scene of anomaly detection. The general framework looks like this:
- Train a model on the sequence
- Predict the future while collecting errors
- Identify anomalies using a non-parametric heuristic
- Post-hoc pruning of false positives based on identified anomalies
Even though their method has less knobs to worry about, it still does not feel auto-pilotish while reading the document. Well, that is supposed to happen I guess.
4.17. READ Snorkel: Rapid training data creation with weak supervision
CUSTOM_ID: ratner2017snorkel
YEAR: 2017
AUTHOR: Ratner, Alexander and Bach, Stephen H and Ehrenberg, Henry and Fries, Jason and Wu, Sen and R{\'e}, Christopher
This one has bunch of practical upgrades on the original data programming paper. Two major things here involve:
- deciding when to use the generative model (as compared to voting)
- tackling correlation
On a side note, while looking at the results you might find that even majority voting (which is very easy to implement) might not be that bad if you are a little careful.
4.19. The tradeoffs of large scale learning
CUSTOM_ID: bottou2008tradeoffs
YEAR: 2008
AUTHOR: Bottou, L{\'e}on and Bousquet, Olivier
4.20. READ Data programming: Creating large training sets, quickly
CUSTOM_ID: ratner2016data
YEAR: 2016
AUTHOR: Ratner, Alexander J and De Sa, Christopher M and Wu, Sen and Selsam, Daniel and R{\'e}, Christopher
Main idea is to focus on creating \(O(1)\) labelling functions on boundless data to get similar asymptotes as compared to labeled data setting.
This same change of focus has another side effect which I agree with:
One of our hopes is that a user without expertise in ML will be more productive iterating on labeling functions than on features.
4.21. READ Harnessing nonlinearity: Predicting chaotic systems and saving energy in wireless communication
CUSTOM_ID: jaeger2004harnessing YEAR: 2004 AUTHOR: Jaeger, Herbert and Haas, Harald
This is the Echo State Network paper (probably not the original one but sufficiently close). I found it to be a little different than what I had earlier thought about there being separate inputs and outputs.
4.22. READ Adversarial examples that fool both computer vision and time-limited humans
CUSTOM_ID: elsayed2018adversarial YEAR: 2018 AUTHOR: Elsayed, Gamaleldin and Shankar, Shreya and Cheung, Brian and Papernot, Nicolas and Kurakin, Alexey and Goodfellow, Ian and Sohl-Dickstein, Jascha
This is an interesting one. Specially since it utilizes the multiple passes thing that happens in human perception.
4.23. READ Datasheets for datasets
CUSTOM_ID: gebru2018datasheets
YEAR: 2018
AUTHOR: Gebru, Timnit and Morgenstern, Jamie and Vecchione, Briana and Vaughan, Jennifer Wortman and Wallach, Hanna and Daume{\'e} III, Hal and Crawford, Kate
I had read this earlier too if I recall, but this time we ended up incorporating the idea in our workplace. This has been helpful since the new datasheet approach makes it really easy to disentangle problems so that people can work on them very cleanly.
4.24. READ NBDT: Neural-Backed Decision Trees
CUSTOM_ID: wan2020nbdt YEAR: 2020 AUTHOR: Wan, Alvin and Dunlap, Lisa and Ho, Daniel and Yin, Jihan and Lee, Scott and Jin, Henry and Petryk, Suzanne and Bargal, Sarah Adel and Gonzalez, Joseph E
This is a nifty trick where we change loss of a regular network to mimic a decision tree type interpretation of output. Source here.
4.25. READ Designing and deploying online field experiments
CUSTOM_ID: bakshy2014designing YEAR: 2014 AUTHOR: Bakshy, Eytan and Eckles, Dean and Bernstein, Michael S
Read this to know more about how planout is used in real world systems.
4.26. READ The unreasonable effectiveness of data
CUSTOM_ID: halevy2009unreasonable YEAR: 2009 AUTHOR: Halevy, Alon and Norvig, Peter and Pereira, Fernando
4.27. READ A credit assignment compiler for joint prediction
CUSTOM_ID: chang2016credit YEAR: 2016 AUTHOR: Chang, Kai-Wei and He, He and Ross, Stephane and Daume III, Hal and Langford, John
This talks about an API for framing L2S style search problems in style of an imperative program which allows for two optimizations:
- memoization
- forced path collapse, getting losses without going to the last state
Main reduction that happens here is to a cost-sensitive classification problem.
4.28. A decision-theoretic generalization of on-line learning and an application to boosting
Custom_ID: freund1997decision AUTHOR: Freund \& Schapire JOURNAL: Journal of computer and system sciences YEAR: 1997 VOLUME: 55 PAGES: 119--139
5. Computing/Programming
5.1. READ Lakehouse: A New Generation of Open Platforms That Unify Data Warehousing and Advanced Analytics
CUSTOM_ID: armbrust2021lakehouse DATE: 2021 AUTHOR: Armbrust, Michael and Ghodsi, Ali and Xin, Reynold and Zaharia, Matei
Got some high level idea about the concept of delta lake here.
5.2. READ Nobody ever got fired for buying a cluster
CUSTOM_ID: appuswamy2013nobody YEAR: 2013 AUTHOR: Appuswamy, Raja and Gkantsidis, Christos and Narayanan, Dushyanth and Hodson, Orion and Rowstron, Ant
5.3. READ Metaobject protocols: Why we want them and what else they can do
CUSTOM_ID: kiczales1993metaobject YEAR: 1993 AUTHOR: Kiczales, Gregor and Ashley, J Michael and Rodriguez, Luis and Vahdat, Amin and Bobrow, Daniel G
This provides a wider perspective on MOP. Specially the sections on Scheme extension techniques clarified that MOP is a very general way of creating an extension system for something else.
5.4. READ Reflections on trusting trust
CUSTOM_ID: thompson1984reflections YEAR: 1984 AUTHOR: Thompson, Ken and others
I remember reading this or watching the talk 3-4 years earlier but not understanding what Ken was trying to say. This time it was fine. I like this top blurb:
To what extent should one trust a statement that a program is free of Trojan horses? Perhaps it is more important to trust the people who wrote the software.
5.5. READ Online aggregation
CUSTOM_ID: hellerstein1997online YEAR: 1997 AUTHOR: Hellerstein, Joseph M and Haas, Peter J and Wang, Helen J
I was looking into this while looking for prior works that provide streaming
results from a database. The idea is to have always available results for
aggregation queries like SUM, COUNT etc. along with uncertainty measurements
based on the currently sampled tuples. Other than the uncertainty estimation
formulations, they presented work on the implementation side of the idea which
involves random sampling and various UX niceties.
5.6. READ Practical type inference based on success typings
CUSTOM_ID: lindahl2006practical YEAR: 2006 AUTHOR: Lindahl, Tobias and Sagonas, Konstantinos
The general idea is to allow all programs that throw no runtime errors. This is specially useful in languages which are philosophically dynamic. I like this approach towards types since programming in a dynamic language involves dropping a lot of so called writer's 'intention' here and there which does not adhere to the static type philosophy.
Not sure if this is one of the firsts (the first for functional languages according to the paper), but these days there are many mainstream dynamic languages adopting such soft typing systems in some form.
5.7. READ Dynamically typed languages
CUSTOM_ID: tratt2009dynamically YEAR: 2009 AUTHOR: Tratt, Laurence
A basic and exhaustive intro to dynamic typed languages. Good for beginners.
5.8. READ Growing a language
CUSTOM_ID: steele1999growing YEAR: 1999 AUTHOR: Steele, Guy L
This is originally a talk, I read a pdf version. An interesting thing is the way the talk itself is structured (its vocabulary mostly) exemplifying the same growth mechanism that Guy talks about in relation to languages.
5.9. READ BlinkDB: queries with bounded errors and bounded response times on very large data
CUSTOM_ID: agarwal2013blinkdb YEAR: 2013 AUTHOR: Agarwal, Sameer and Mozafari, Barzan and Panda, Aurojit and Milner, Henry and Madden, Samuel and Stoica, Ion
I find works like this, and other approximate query processing systems, pretty interesting since their general structures are close to machine learning systems with slightly different metrics to be optimized. This, of course, then provides a lot of food for thought.
So, what BlinkDB does is pretty clear from the title. On the how side, they
basically create a bunch of samples (table subsets) based on criterion derived
from past queries. The 'key' for samples here are sets of columns involved in
the queries' WHERE, HAVING etc. clauses. When asked a query with timing, error
requirements, a sample is picked (after some estimation on some data; this is
important, since they don't want to put much assumptions on the type of
workload) and query runs on that.
Since they are mostly for high scale use cases, these methods are not 'very' visible unless you are into such things. Although, I believe, similar ideas (I specially liked the Online Aggregation thing from 1997) can be put in more commonplace, smaller, systems (or already are there).
5.10. Type systems as macros
CUSTOM_ID: chang2017type YEAR: 2017 AUTHOR: Chang, Stephen and Knauth, Alex and Greenman, Ben
5.11. Physics, topology, logic and computation: a Rosetta Stone
Custom_ID: baez2010physics AUTHOR: Baez \& Stay YEAR: 2010
5.12. READ The Genuine Sieve of Eratosthenes
Custom_ID: o2009genuine AUTHOR: O'NEILL JOURNAL: Journal of Functional Programming YEAR: 2009 VOLUME: 19 PAGES: 95--106
This talks about a functional implementation of Sieve of Eratosthenes. Specifically it debunks the following incorrect implementation:
primes = sieve [2..] sieve (p : xs) = p : sieve [x | x <− xs, x `mod` p > 0]
Then we see correct functional implementations with neat tricks made possible due to laziness of Haskell. Although slower, there is a list based implementation by Bird mentioned in the Epilogue which is pretty readable (and elegant) and follows very closely the following description:
primes = [2, 3, ...] \ [[p², p²+p, ...] for p in primes]
5.13. READ Why functional programming matters
Custom_ID: hughes1989functional AUTHOR: Hughes JOURNAL: The computer journal YEAR: 1989 VOLUME: 32 PAGES: 98--107
This is a famous paper and I wanted to see what it focuses on. It's basically about the following two properties and their effect on modularity in functional programmings:
- Higher order functions
- Lazy evaluation
The examples are nice and make this is a good read for beginners. Though I suspect there might be better, recent, articles on these topics now.
6. Misc
6.1. READ How to do research at the MIT AI lab
CUSTOM_ID: chapman1988research YEAR: 1988 AUTHOR: Chapman, David
A bit dated but has nice nuggets of wisdom. I like simple pointers like "writing is debugging" which provides a different perspective to the way a few trivial things are done.
Thanks to Jaydeep for pointing me to this.
6.2. READ How do committees invent
CUSTOM_ID: conway1968committees YEAR: 1968 AUTHOR: Conway, Melvin E
Original paper on Conway's Law. The reasoning used is easy to understand and feels trivial in hindsight but there are nice nuggets scattered in between, like the following, which makes the reading worthwhile:
A manager knows that he will be vulnerable to the charge of mismanagement if he misses his schedule without having applied all his resources.
6.3. READ More is different
CUSTOM_ID: anderson1972more YEAR: 1972 AUTHOR: Anderson, Philip W and others
The basic idea is the following:
The main fallacy in this kind of thinking is that reductionist hypothesis does not by any means imply a "constructionist" one.
We are trying to understand that reductionist view is not going to explain everything and that fundamental laws at the lowest level are not going to be the fundamental ones for the higher level ("Psychology is not applied biology…"). A littl0e hierarchy is also presented using examples where our movements across levels results in broken symmetry:
- Crystallinity
- Functional structures
- Regular systems with information like DNA
- Ordering in the time dimension for information processing etc.
So it is not true, as a recent article would have it, that we each should "cultivate out own valley, and not attempt to build roads over the mountain ranges … between the sciences." Rather, we should recognize that such roads, while often the quickest shortcut to another part of our own science, are not visible from the viewpoint of one science alone.
6.4. READ Google's hybrid approach to research
CUSTOM_ID: spector2012google YEAR: 2012 AUTHOR: Spector, Alfred and Norvig, Peter and Petrov, Slav
Mostly about the people being researchers and developers and how it affects various aspects of experiments.
6.5. READ Machine learning: The high-interest credit card of technical debt
CUSTOM_ID: sculley2014machine YEAR: 2014 AUTHOR: Sculley, D and Phillips, Todd and Ebner, Dietmar and Chaudhary, Vinay and Young, Michael
6.6. READ Better science through art
CUSTOM_ID: gabriel2010better YEAR: 2010 AUTHOR: Gabriel, Richard P and Sullivan, Kevin J
Here are the last few lines which cover what's common between Science and Art and also summarize the document:
- Explore: wander / defamiliarize
- Discover: guess / abduce
- Understand: validate / ask—did you build the right thing?
6.7. READ Lisp, Jazz, Aikido–Three Expressions of a Single Essence
Custom_ID: verna2018lisp AUTHOR: Verna JOURNAL: arXiv preprint arXiv:1804.00485 YEAR: 2018
Okay, this was up on /r/lisp, felt not that much effort to read so I gave it a shot. There are three general aesthetic avenues that the author covers:
- Conformation
- Transgression
- Unification
The general idea is about the similar interplay of these in all the 3 things (Lisp, Jazz & Aikido) and how they end up being a source of pleasure and enlightenment.
From whatever I have felt, things that focus on an act itself (rather than prioritizing the results) end up being like these (well, probably this is obvious).
This paper is a quick read and is not overly philosophical. Maybe that's because one of the focus is on tools that stay out of your way by staying practical (you can see this when the author talks about Common Lisp specifically). Although I must say that I know next to nothing about both Jazz and Aikido so might not have really been able to connect all the pieces.
Footnotes:
Might have missed somewhere or there might be mentions in prior works